《表2 结果比较:基于系统聚类和SVM模型的乳腺癌诊断研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
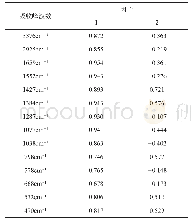
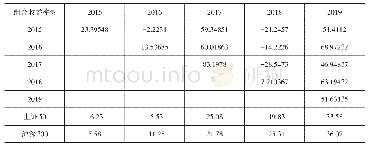
就准确率而言,本文提出的H-SVM算法与仅使用SVM算法进行分类比较,保证了高的预测精度;另一方面,H-SVM算法是通过将原始数据进行特征选择以减少特征空间的维度,然后特征重建转换为新的数据集。从计算时间的角度来看,所提出的方法通过减少输入特征的数量,显著减少了训练时间。表2中将计算时间与传统的SVM算法进行了比较,显示了选择和提取特征的重要性。
| 图表编号 | XD00192305300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.11.01 |
| 作者 | 余莹、樊重俊、朱人杰、熊红林 |
| 绘制单位 | 上海理工大学管理学院、上海理工大学管理学院、上海理工大学管理学院、同济大学附属东方医院、上海理工大学管理学院、万达信息股份有限公司 |
| 更多格式 | 高清、无水印(增值服务) |

{kind=link}