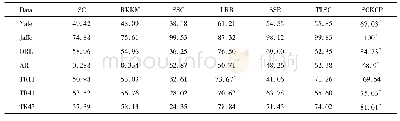
《表1 停留点数据集上聚类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
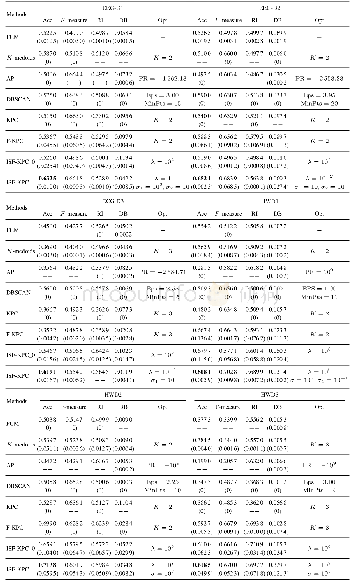
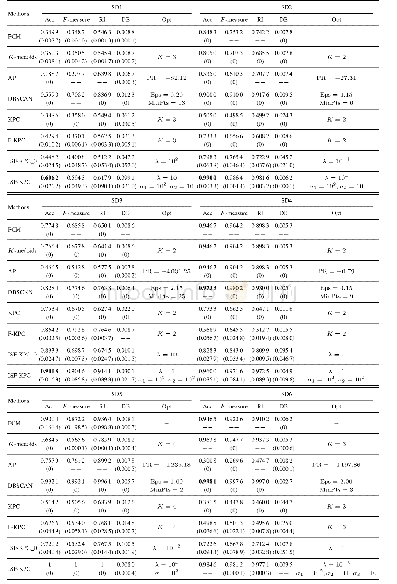
从运行时间来看,K-means算法耗费时间最短,而ISCRM算法最长;但在轮廓系数指标中,K-means算法及DBSCAN算法均不及ISCRM算法高,且试验结果也不如ISCRM算法稳定。对比表1中各聚类算法在停留点数据集上的表现,尽管K-means和DBSCAN算法运行时间较短,但在其繁琐的参数选取环节上会耗费额外的时间。而ISCRM算法依据自适应局部参数σi描述样本实际分布,以及自动估计聚类数目,可获得更贴近样本真实分布的特征向量空间,并对特征空间进行聚类,也在一定程度上加快了收敛速度。ISCRM算法通过自适应调节参数直接获得的结果轮廓系数最高,代表聚类结果最合理。
| 图表编号 | XD00190103900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2021.01.15 |
| 作者 | 梁卓灵、元昌安、覃晓、乔少杰、韩楠、范勇强 |
| 绘制单位 | 广西大学、南宁师范大学、南宁师范大学、成都信息工程大学、成都信息工程大学、成都市环境保护信息中心 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}