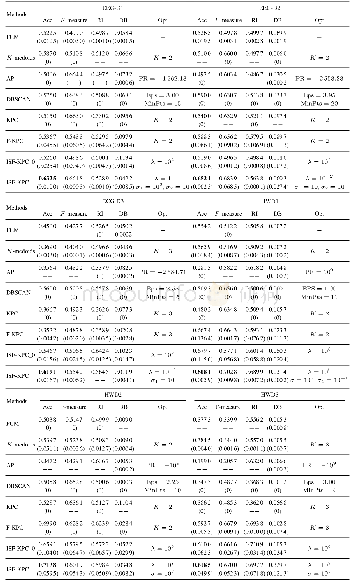
《表5 所有对比算法在真实数据集上的详细聚类结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
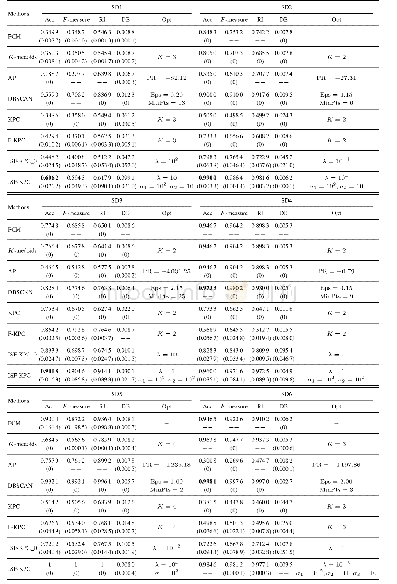
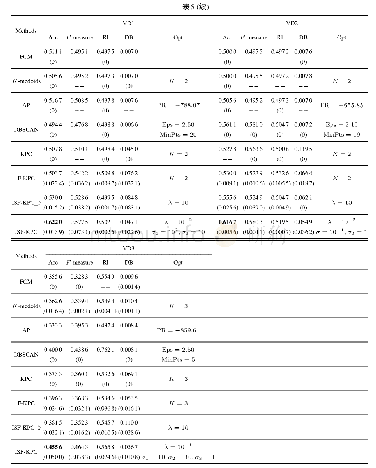
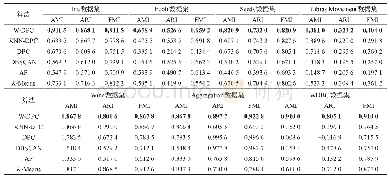
该统计测试方法主要包含FF和CD两个关键值[27].FF用于确定该统计测试方法的空假设(即假设所有对比算法具有相同的聚类性能)是否被否定;CD用于验证对比算法之间的聚类性能是否存在显著区别.由表5列出的聚类正确率对所有对比算法进行排序,如对于EEG-D2,因ISF-KPC取得了最好的聚类结果,其排名为1,即rank=1.依此类推,可得出所有对比算法在所有真实数据集上的排序,如表6所示.根据对比算法排序值、F-分布及其自由度(Nc-1)、(Nc-1)(Nd-1)可确定FF值.只要满足FF>F((Nc-1),(Nd-1)),该统计测试方法的空假设即被否定.其中Nc代表所有对比算法个数,Nd代表真实数据集个数,F(·,·)根据F-分布表可查出[27].基于空假设被否定,可进一步计算CD值.其中(α为显著性度,其值取文献[27]推荐值α=0.05,qα可从文献[27]查出).任意两个对比算法平均排序差值的绝对值大于该CD值即表明这两个对比算法的聚类性能之间存在显著区别.
| 图表编号 | XD00165480400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.01 |
| 作者 | 顾苏杭、王士同 |
| 绘制单位 | 江南大学数字媒体学院、常州轻工职业技术学院信息工程与技术学院、江南大学数字媒体学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}