《表3 在基准数据集上获得的聚类结果NMI》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:最佳结果用“*”标出。
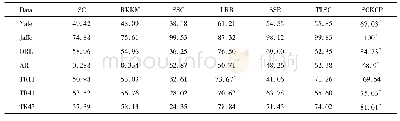
将本文提出的算法与谱聚类(Spectral Clustering,SC)[3]、鲁棒核K-means (Robust Kernel K-means,RKKM)[2]、单纯形稀疏表示(Simplex Sparse Representation,SSR)[6]、低秩表示(Low-Rank Representation,LRR)[5]、稀疏子空间聚类(Sparse Subspace Clustering,SSC)[1]、相似性和聚类的孪生学习(Twin Learning for Similarity and Clustering,TLSC)[13]在7个基准数据集上进行比较,结果如表2和表3所示。SCKCP在ACC和NMI两个聚类评价指标上,除数据集TR11的ACC略微降低,其余聚类性能均优于对比算法。在Jaffe数据集上ACC和NMI达到100%。我们发现SCKCP的性能不仅高于目前流行的单核聚类算法,而且高于如文献[14]中流行的多核聚类算法。以上对比算法大都以学习一个相似矩阵为主,相似矩阵质量将是聚类精度的关键。
| 图表编号 | XD00227249300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.30 |
| 作者 | 黄治力、谌永祥、李永桥 |
| 绘制单位 | 西南科技大学制造科学与工程学院、西南科技大学制造科学与工程学院、西南科技大学制造科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}