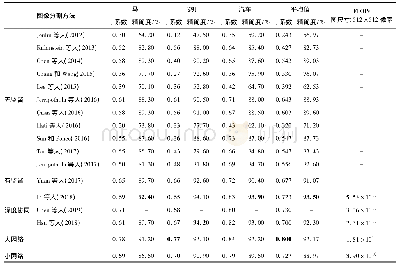
《表3 第二个数据集上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
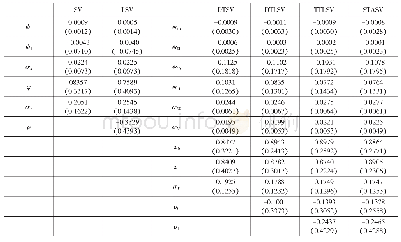
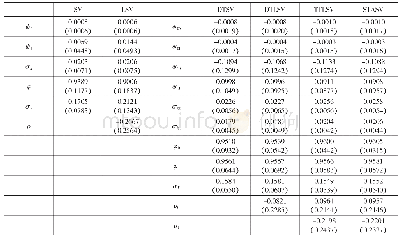
没有一个模型能够在对所有数据集的这些分类问题上都取得最优性能,原因是不同的权值生成方法在每个数据集上会产生不同的权值分布。最优的模型是能够在每个数据集中对每个收益性不同的实例生成最适合的惩罚模型。因此,本文建议应该尝试所有可选的误差函数,以决定针对某一数据集性能最优的模型。同时,传统的基于分类的代价敏感性ANN模型在节约(收益)项上没有保持相当的一致性,而本文提出的模型在总收益项上显著优于该模型。
| 图表编号 | XD00189233000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.12.05 |
| 作者 | 孙林娟、贾月辉 |
| 绘制单位 | 天津大学仁爱学院计算机科学与软件系、天津中德应用技术大学软件与通信学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}