《表1:训练、验证、测试结果(括号中的百分比为准确率)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
模型主要是以文本作为信息输入,旨在挖掘出文本中的隐含特征,获取微博文本的向量表达。由于从微博爬取的文本无法直接输入人工神经网络模型,且这些没有经过处理的文本数据中有很多冗余信息,会影响分类效果和效率。所以要进行中文文本的预处理,如中文分词、停用词过滤、词语向量化等[3]。为了节约人工处理数据时间,同时加快信息处理能力,本文使用Python程序对文本数据进行进一步处理,jieba作为目前最好的Python中文分词组件,它的精确模式可以在进行中文分词后还可以进行去标点、去空格、去停用词等处理,最终使得文本串变成一系列有效词语的集合[4]。
| 图表编号 | XD00184738000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.09.15 |
| 作者 | 朱颖 |
| 绘制单位 | 南京林业大学 |
| 更多格式 | 高清、无水印(增值服务) |

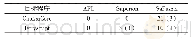




{kind=link}