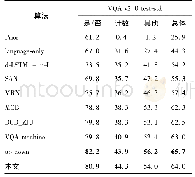
《表3 在VQA v2.0 validation上不同多模态融合方式比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体为最优结果。
实验在将记忆网络的最终输出mT与问题q联合嵌入的过程中,还比较了不同的多模态融合方式对视觉问答结果的影响,在VQA v2.0数据集的验证集上对模型进行评估。如表3所示,比较了3种不同的多模态融合方式,第1种方法将mT与q相串联;第2种方法将mT与q分别输入到非线性全连接层,然后将输出结果进行Hadamard乘积;第3种方法将mT与q分别输入到非线性全连接层,然后将输出结果串联。从表3可以看出,采用第3种融合方式的准确率较高,与第1种和第2种方法相比,准确率分别提高了0.15%和0.43%,因此本文模型使用第3种融合方式。
| 图表编号 | XD00179360000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.16 |
| 作者 | 闫茹玉、刘学亮 |
| 绘制单位 | 合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}