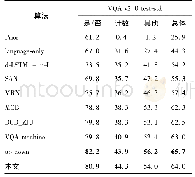
《表1 不同算法在VQA v2.0 test-std测试集上的准确率比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
注:加粗字体为每列最优结果。
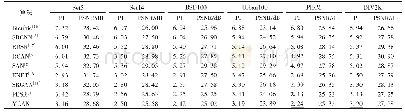
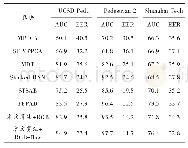
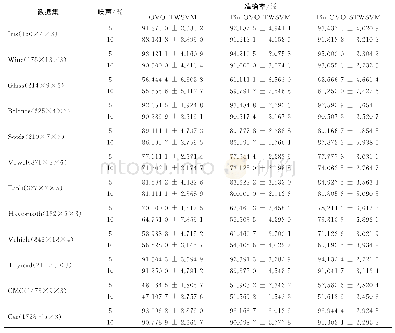
在VQA v2.0的test-std测试集上,选取9种现有代表性的视觉问答模型与本文模型进行比较,包括两大基线模型prior(Antol等,2015)和languageonly(Antol等,2015)及d-LSTM+n-I(deeper LSTM and normalized image)(Lu等,2015)、SAN(stacked attention networks)(Yang等,2016)、MRN(multimodal residual networks)(Kim等,2016)、MCB(multimodal compact bilinear)(Fukui等,2016)、DCD_ZJU(Lin等,2017)、VQA machine(Wang等,2017)、updown(Anderson等,2018)等主流算法。表1列出了所有比较算法的准确率,从总体及“是/否”、“计数”、“其他”问题类别上,对算法性能进行比较。可以看出,本文模型的总体准确率与up-down模型相接近,二者均高于其他算法。在视觉问答任务中,与其他算法相比,本文模型的准确率有显著提升。与早期的基线模型prior、language-only、d-LSTM+n-I相比,总体准确率分别提高38.1%、19.7%、9.8%;与后期引入注意力机制的SAN和DCD_ZJU算法相比,总体准确率分别提高8.7%和1.5%;与引入多模态残差网络的MRN算法相比,总体准确率提高6.6%;与提出新的多模态特征融合的MCB算法相比,总体准确率提高1.7%;相比于性能较好的VQA machine算法,本文模型总体及回答“是/否”、“计数”、“其他”问题的准确率分别提高了1%、1.1%、3.4%和0.6%,在总体和3个不同问题类别上,本文模型在视觉问答任务中都取得了不错效果。
| 图表编号 | XD00179359900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.16 |
| 作者 | 闫茹玉、刘学亮 |
| 绘制单位 | 合肥工业大学计算机与信息学院、合肥工业大学计算机与信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}