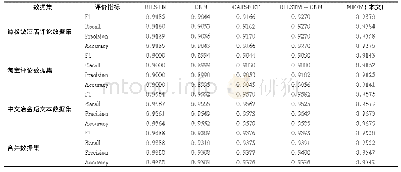
《表6 三个数据集上的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
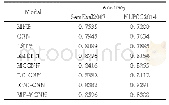
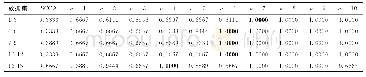
为验证MFFM的性能,本文与短文本分类中的四个经典模型CNN、BILSTM、CAPSNET和CNN-BILSTM作为基准模型进行对比实验,实验结果如表6所示,模型的F1值如图2所示.通过对表6和图2的分析,可以看出MFFM在三个中文短文本数据集上的分类性能均优于四个基准模型.其中,在谭松波酒店评论数据集上MFFM相比基准模型中的最优模型BILSTM-CNN的F1值提升了1%;在淘宝评论数据集上,相比BILSTM-CNN模型F1值提升0.93%;在中文冶金短文本数据集上,相比BILSTM-CNN模型F1值提升0.94%.为了进一步证明本文提出模型的有效性,本文在实验部分对中文短文本数据集、谭松波酒店评论数据集和淘宝评论数据集三个数据集的正负样本进行合并构建新的数据集,合并后的数据集含有不同领域之间的正负样本,相比单个数据集具有更好的兼容性,通过表6可以看出,本文提出的模型在融合后的数据上,相比基准模型中的最优模型BILSTM-CNN的F1提升了1.55%,通过在单一领域数据集和多领域数据上的实验结果可以看出本文提出的模型相比基准模型均有一定程度的提高,从而有效的证明了本文提出模型MFFM的有效性.
| 图表编号 | XD00175975400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 杨朝强、邵党国、杨志豪、相艳、马磊 |
| 绘制单位 | 昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院、昆明理工大学信息工程与自动化学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}