《表2 限时语法判断测试的预测性回归模型》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
**p<.01,*.01≤p<.05
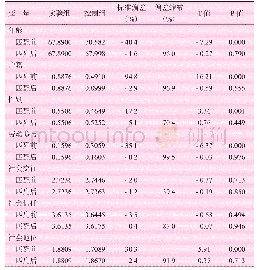
我们采用多元逐步回归分析来检测个体差异因素对二语内隐知识的预测性。口头诱导模仿测试和限时语法判断测试成绩均为因变量。二语起始年龄、语言分析能力、学习动机及其两个内部构念、学习信念及其三个内部构念为自变量(分析结果见表1和表2)。由表1可见,起始年龄、语言分析能力、内在兴趣动机及与情感状态相关的信念进入口头诱导模仿测试预测性回归模型,对该测试成绩具有较强预测性(调整后的决定系数R2=.285,统计量的显著值F=.000)。采用调整后的决定系数R2的原因在于应用于现实时,决定系数R2往往会高估模型的成功率。而调整后的决定系数R2则将模型中变量和观察值的数量均考虑在内,比较符合实际。回归系数Beta表示每个预测变量对因变量的影响程度,其绝对值越大,对因变量的影响程度越高,其解释因变量的变异量也就会越大。表中可见,与情感状态相关的信念预测性最强,起始年龄紧随其后。表2则显示,与情感状态相关的信念和内在兴趣动机进入限时语法判断测试预测性回归模型,对该测试成绩具有较强的预测性(调整后的决定系数R2=.136,统计量的显著值F=.002)。其中内在兴趣动机的预测性最强。
| 图表编号 | XD00174908200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 张润晗、陈亚平 |
| 绘制单位 | 北京外国语大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}