《表3 声学模型为音节的13维MFCC特征训练模型的识别率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
提取的特征参数MFCC为13维,声学模型分别为音节、声韵母,按表1所示音节的状态个数设定为6,声母的状态个数设定为3,韵母的状态个数设定为6,不同高斯分量个数训练好的的HMM对语料库中训练集和测试集分别进行了测试,识别结果如表3和表4所示。
| 图表编号 | XD00174773400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.25 |
| 作者 | 蒋正锋、黄勇萍 |
| 绘制单位 | 广西民族师范学院数学与计算机科学学院、广西民族师范学院数学与计算机科学学院 |
| 更多格式 | 高清、无水印(增值服务) |

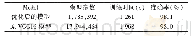




{kind=link}