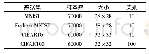
《表2 基于约减的SVM算法对不同数据量的约减率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
之所以使用7种算法来进行检测,是因为不同机器学习算法对于流量数据处理场景的适用程度不同.SVM的检测结果最好,意味着其更加适用于异常流量检测的分类场景.因此,本文使用SVM算法对不同数量的流量数据进行检测,其中,对10万、20万、30万、40万、50万条流量数据的约减效果如表2所示.由表2可知,数据约减率呈现为先上升后下降的趋势,当流量数据为20万条时,数据约减量达到峰值,约减率为47.58%.因此,基于层次聚类的流量异常检测模型的最佳数据量处理切片为20万条.对于新的需预测的流量数据,以20万条数据量作为划分区间,将其划分为多段流量信息,再使用基于层次聚类的流量异常检测模型进行检测,能够在保留较高精准率的情况下,提升召回率,达到最好的约减效果.
| 图表编号 | XD00174273600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.05 |
| 作者 | 蹇诗婕、卢志刚、姜波、刘玉岭、刘宝旭 |
| 绘制单位 | 中国科学院信息工程研究所、中国科学院大学网络空间安全学院、中国科学院信息工程研究所、中国科学院大学网络空间安全学院、中国科学院信息工程研究所、中国科学院信息工程研究所、中国科学院大学网络空间安全学院、中国科学院信息工程研究所、中国科学院大学网络空间安全学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}