《表1 混淆矩阵:基于线性LTSA算法维数约减的软件缺陷预测研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
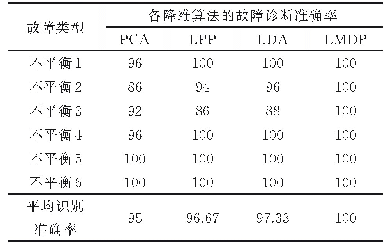
软件缺陷预测技术领域最广泛应用二维混淆矩阵评价模型的预测能力,是国际上公认的、标准化的研究方法,实验中SVM分类可以得到每个样本的标签信息,即有缺陷1或者无缺陷-1,将1预测为-1的数目记为TP,将1预测为-1的数目记为FN,将-1预测为1的数目记为FP,将-1预测为1的数目记为TN,统计得到TP、TN、FP和FN的值.计算得到指标包括准确度、查全率、查准率和F-measure值,本模型主要采用准确度这一评价指标.如表1所示.
| 图表编号 | XD0045714300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.01.10 |
| 作者 | 王玉红、范菁、曲金帅、冯景义 |
| 绘制单位 | 云南民族大学云南省高校信息与通信安全灾备重点实验室、云南民族大学云南省高校信息与通信安全灾备重点实验室、云南民族大学云南省高校信息与通信安全灾备重点实验室、云南民族大学云南省高校信息与通信安全灾备重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}