《表2 结果回归模型和倾向性得分模型设定都错误时95%置信区间覆盖率随γ的变化》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
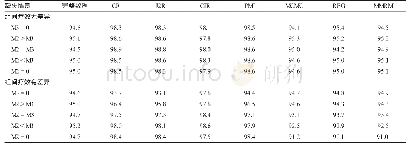
当结果回归模型和倾向性得分模型的设定都错误时,附图1至附图6显示AIPW和CB的偏差、方差,都会随着γ的变大所引起的公共支撑变差而变差,CB在结合超级学习算法后的估计精度有所提升,但仍远逊于本文提出的两种方法(CBDR+SL与MFCBDR+SL),并且本文的两个结果十分接近,二者的偏差几近于0。表2、5、6展示了本文的两种方法的95%置信区间覆盖率,其中表5、6显示,当倾向性得分服从误差项为t分布的Probit模型时,当γ较大即较多极端倾向性得分存在时,本文所提的两种方法的偏差仍很小,但95%置信区间覆盖率低于0.95。附图3、附图5中显示AIPW的偏差非常大,在ATE真值是0.75的情况下,其偏差基本都超过了1。但由于AIPW的方差估计值偏大(附图4、附图6),导致其置信区间覆盖率反而更接近0.95(表3、4);相较而言,本文两种方法的偏差和方差估计值都很小。表3展示了在较多极端倾向性得分情景下(γ=4),随着样本量的增加,本文的两种方法的偏差与估计的方差都具有减少趋势,并且在样本量为500时就已经表现很出色了。尽管在以上的模拟中结果Y与倾向性得分π(X)均使用了错误模型,但本文的两种方法的模拟结果仍然出色,优于目前处理存在极端倾向性得分的几种估计方法,当然这里借助超级学习算法也提升了估计的精度。
| 图表编号 | XD00172926900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.25 |
| 作者 | 吴浩、彭非 |
| 绘制单位 | 中国人民大学统计学院 |
| 更多格式 | 高清、无水印(增值服务) |

![表2 BMI随年龄变化轨迹与高血压患病关联的Cox比例风险回归模型[HR(95%CI)]](http://bookimg.mtoou.info/tubiao/gif/QKYX202108026_02500.gif)
{kind=link}