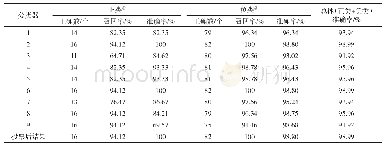
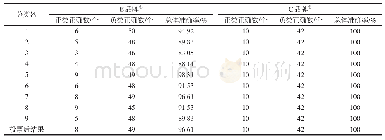
《表8 机器学习个人征信模型测试结果比较》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
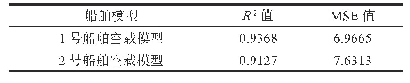
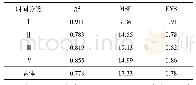
采用Pyhton3.6.0软件,根据常规搜索算法调整模型参数,将数据随机分成训练数据和测试数据两份,比例为7∶3。训练数据用于训练模型,测试数据用于对模型进行评价。评价指标主要包括准确率、召回率和F1值。准确率是评估捕获的成果中目标成果所占得比例;召回率是从关注领域中召回目标类别的比例;F1值则是综合这二者指标的评估指标,用于综合反映整体的指标。结果如表8所示。
| 图表编号 | XD00172476600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.15 |
| 作者 | 张晖、张志明 |
| 绘制单位 | 铜陵学院金融学院、铜陵学院金融学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}