《表1 数据集总体情况:基于统计特征的Quality Phrase挖掘方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于统计特征的Quality Phrase挖掘方法》
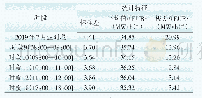
本文选择5个真实数据集作为实验的文本语料库:(1)5Conf包含AI,DB,DM,IR,ML五个领域科技论文的标题文本信息;(2)DBLP Abstracts收集了计算机类文章的摘要信息;(3)AP News是TREC 1998年的新闻文本数据集;(4)AMiner-Titles将AMiner-Paper[22](研究学术信息网络的数据集)中的标题信息抽取出来;(5)AMiner-Abstracts为从AMiner-Paper中抽取出来的摘要语料库。对5个文本语料库进行数据预处理,去除特殊符号、去除停用词、提取词元信息后的数据集基本情况如表1所示。
| 图表编号 | XD00170137400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 杨欢欢、赵书良、李文斌、武永亮、田国强 |
| 绘制单位 | 河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北地质大学信息工程学院、河北师范大学数学科学学院、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}