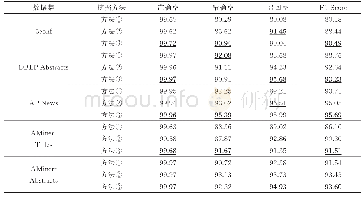
《表3 候选短语挖掘3个阶段对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
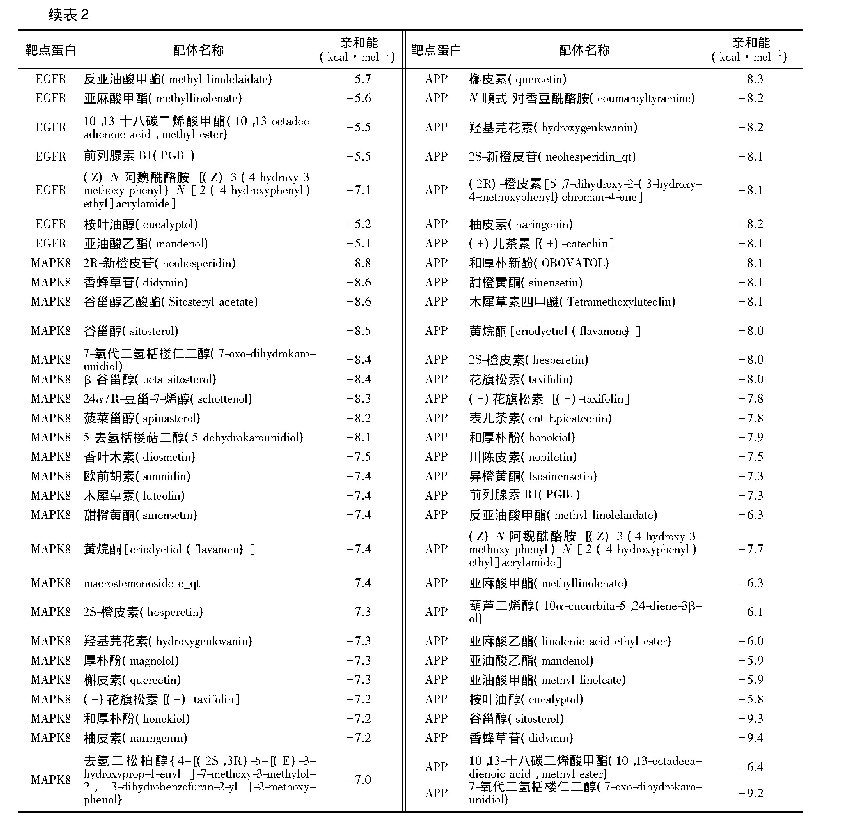
《基于统计特征的Quality Phrase挖掘方法》
%
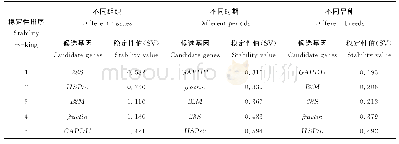
从5个文本语料库呈现的PR曲线可以看出,单使用频繁性一个准则进行N-Gram短语挖掘时,精确率和召回率的结果受频繁性阈值的影响极大,鲁棒性差。若设置的频繁性阈值较大,精确率可以达到较高的水平,但是召回率很低;相反,频繁性阈值设置较小时,召回率很高,可以达到90%以上,但是精确率明显下降。所以,单使用频繁性一个准则,很难达到精确率和召回率的平衡。为解决频繁性准则带来的问题,加入多词短语的组合性约束,两者的结合可以使5个数据集上的精确率稳定在一个较好的区间,基本维持在90%~100%,此时保证在精确率不明显下降的情况下,不断调节频繁性阈值来提升召回率,寻找最优的参数组合。在频繁N-Gram挖掘和多词短语组合性约束的基础上,增加单词短语的拼写检查可以进一步提高精确率,虽然拼写检查错误地排除了一部分真正的单词,导致召回率有所下降,但综合性指标F1-Score仍然是上升趋势。下面将5个文本语料库在3种递进组合(方法(1)表示频繁N-Gram挖掘,方法(2)表示频繁N-Gram挖掘+多词短语组合性约束,方法(3)表示频繁N-Gram挖掘+多词短语组合性约束+单词短语拼写检查)上的最优结果列举如表3所示。
| 图表编号 | XD00170137500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 杨欢欢、赵书良、李文斌、武永亮、田国强 |
| 绘制单位 | 河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北地质大学信息工程学院、河北师范大学数学科学学院、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |
![表1 两组患者在3个阶段血糖浓度变化情况对比[(±s),mmol/L]](http://bookimg.mtoou.info/tubiao/gif/TNBX202015024_01300.gif)

{kind=link}