《表2 数据集信息:基于伪F统计量的属性特征降维方法研究》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
从表2可以看出,每个数据集的样本数和特征数不尽相同,Pima数据集特征最少有7个,而Sonar包含60个特征.借助于构造的(2)式伪F统计量计算每个数据的输入特征的重要程度,根据特征重要性累积比率确定最终的属性提取个数.
| 图表编号 | XD00148485800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.20 |
| 作者 | 刘文博、梁盛楠、余泉、董小刚 |
| 绘制单位 | 黔南民族师范学院数学与统计学院、黔南民族师范学院数学与统计学院、黔南民族师范学院数学与统计学院、长春工业大学数学与统计学院 |
| 更多格式 | 高清、无水印(增值服务) |

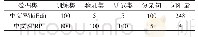



{kind=link}