《表1 数据集基本信息:结合词向量和统计特征的专利相似度测量方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为验证所提模型的有效性,利用国家知识产权局专利数据库,从专利分类号IPC为G06(计算;推算;技术)下5个小类G06F、G06K、G06M、G06Q和G06T各随机下载10 500篇包含专利标题和专利摘要的中国发明公开专利文本,每个小类的500篇专利作为待分析专利文本集,总计2 500篇待分析专利文本;剩余10 000篇作为辅助专利文本集,总计50 000篇专利文本。数据集统计信息如表1所示。
| 图表编号 | XD00107787600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.09.25 |
| 作者 | 俞琰、陈磊、姜金德、赵乃瑄 |
| 绘制单位 | 南京工业大学信息服务部、东南大学成贤学院计算机工程系、南京工业大学信息服务部、南京晓庄学院经济与管理学院、南京工业大学信息服务部 |
| 更多格式 | 高清、无水印(增值服务) |



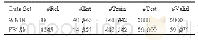
{kind=link}