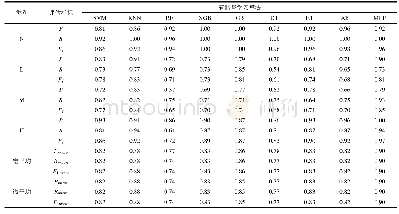
《表5 基于伪F统计量特征选择算法的5FCV-KKNN分类预测性能评价》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
%
在对输入变量的重要程度进行计算度量后,接下来采用目前一些主流的有监督机器学习方法对数据集进行分类预测.首先,利用加权K最近邻(KKNN)在排序后的不同特征子集下对Pima数据集进行5折交叉验证(5FCV),相应的性能指标如表5.需要说明的是,之所以首先选择K近邻方法,主要是因为该方法对于低维数据分类效果较好,一旦维度逐步升高其分类性能就会下降.对于此类机器学习算法,有效降低特征空间的维度,是其理想应用的前提保证.
| 图表编号 | XD00148486400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.20 |
| 作者 | 刘文博、梁盛楠、余泉、董小刚 |
| 绘制单位 | 黔南民族师范学院数学与统计学院、黔南民族师范学院数学与统计学院、黔南民族师范学院数学与统计学院、长春工业大学数学与统计学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}