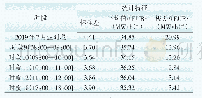
《表2 混淆矩阵:基于统计特征的Quality Phrase挖掘方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于统计特征的Quality Phrase挖掘方法》
目前短语挖掘领域判定一个短语是否为Quality Phrase有两种方式:(1)以维基百科实体为基准;(2)通过领域专家进行评价。本文选择第1种方式,若算法挖掘的短语能够在维基百科中找到一条对应的实体,则认为该短语是真正的Quality Phrase。由这种方式产生的混淆矩阵如表2所示。根据混淆矩阵计算准确率(Accuracy)、精确率(Precision)、召回率(Recall)和F1-Score,作为评价算法优劣的指标。
| 图表编号 | XD00170137300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.05.01 |
| 作者 | 杨欢欢、赵书良、李文斌、武永亮、田国强 |
| 绘制单位 | 河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室、河北地质大学信息工程学院、河北师范大学数学科学学院、河北师范大学计算机与网络空间安全学院、河北师范大学河北省供应链大数据分析与数据安全工程研究中心、河北师范大学河北省网络与信息安全重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}