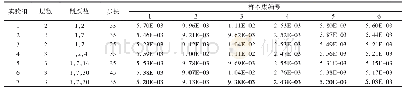
《表2 预测结果的均方误差(MSE)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于共享随机效应和特异稀疏效应的混合多任务学习模型》
在本小节中,我们利用MSS模型对电影评价网站IMDB.com提供的开放数据进行了分析.原始数据来源于IMDB.com网页上的用户电影评论和对应的电影评分.数据共包含25000条电影评论,每条评论都对应一个取值范围0~10的评分,我们这里只提取偏向两极(评分小于4分的负面评论或大于7分的正面评论)的评分对应的评论用于关键词的提取,并且保证正面评论和负面评论的数目相等.全部评论包含的所有不重复的词汇构成了我们需要的词库,其数量对应特征的维度p,每条评论对应一个p维词库向量,评论中出现的所有不重复的词汇在p维词库向量中对应的位置用1表示,其余位置用0表示[33].在本实验中,p=27743,表明全部评论中所有不重复的词汇数共计27743个.电影类型一共选取3种:剧情片、喜剧片和恐怖片,对应的评论数分别为8286,5027和3073.我们用MSS模型构建回归模型,用于对电影评分进行预测和对电影评分有关的关键词进行提取.并将结果与对每一个类型电影进行单独训练的RSS模型、岭回归和Lasso进行对比.利用10折交叉验证的方法对4种算法的结果(电影预测评分的均方误差)进行比较.结果在表2中展示.对于剧情片和喜剧片MSS模型相对另外3种模型有更好的预测结果,这与3.1小节中的实验结果一致.
| 图表编号 | XD00168238200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 彭毫、王雎、王尧 |
| 绘制单位 | 西南财经大学工商管理学院、电子科技大学经济与管理学院、西安交通大学管理学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}