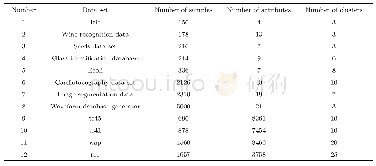
《表1 基准数据集:基于样本稳定性的聚类方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
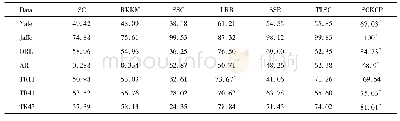
为验证基于样本稳定性的聚类方法在处理聚类任务时的性能,采用来源于UCI数据集的8组数据和来源于CLUTO的4组文本数据,12组数据的详细信息如表1所示.为对照性地显示基于样本稳定性聚类算法(sample’s stability-based clustering,SSC)的聚类性能,8个具有代表性的聚类算法被选为性能参照算法,包括K-means算法、K-means*算法[27]、全局K-means算法(global K-means GK-means)[28]、AP算法、自适应仿射传播聚类算法(adaptive affinity propagation,AD-AP)[29]、DP算法、改进的密度峰值聚类算法(grid-division-based density peak clustering,GDPC)[30]、边界剥离聚类算法(border-peeling clustering,BPC)[31].其中,各类算法均采用固定聚类个数的版本.为降低K-means算法和K-means*算法中随机性对性能评测的影响,运行这两种方法100次并展示其平均性能.本文采用余弦距离处理文本数据.
| 图表编号 | XD00168238300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.20 |
| 作者 | 李飞江、钱宇华、王婕婷、梁吉业、王文剑 |
| 绘制单位 | 山西大学大数据科学与产业研究院、山西大学大数据科学与产业研究院、山西大学计算智能与中文信息处理教育部重点实验室、山西大学大数据科学与产业研究院、山西大学计算智能与中文信息处理教育部重点实验室、山西大学计算智能与中文信息处理教育部重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}