《表5 时间效率对比:基于多粒度粗糙集的聚类融合方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
/s
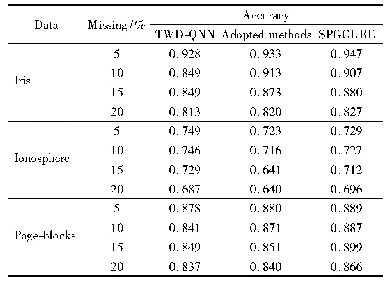
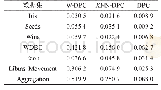
算法的时间效率如表5与图2所示。设每次运行时生成了h个聚类成员,每个聚类成员有K个类,每个类中有p个元素,使用多粒度粗糙集计算边界后,|BN|=|U|-n,则第一步计算相容度矩阵的复杂度为(h Kp)2,第二步Otsu算法的时间复杂度|U|log|U|,第三步求解下近似和边界的比较次数为(Kp)2,第四步对边界域元素重新归类的时间复杂度不大于|U|(|BN|!),所以MGIDA总的时间复杂度为O((h Kp)2)+|U|log|U|+(Kp)2+|U|(|BN|!)),由时间复杂度可知论域大小和聚类类别数目是影响算法运行时间的最重要因素,且边界域较小时算法的时间复杂度较低。由表5与图2可得,MGI-DA在4个数据集上有最好的时间效率,在除第1数据集外的其他数据集上均取得了次优的时间效率,算法的时间复杂度较小。值得注意的是MGIDA在小数据集的时间效率较高,在数据集的数据量增大时表现一般,如图2所示。
| 图表编号 | XD0090319700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 于佩秋、李进金、林国平 |
| 绘制单位 | 闽南师范大学数学与统计学院、福建省粒计算重点实验室、闽南师范大学数学与统计学院、闽南师范大学数学与统计学院、福建省粒计算重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}