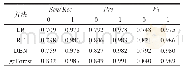
《表2 混合采样前的4种模型性能指标》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
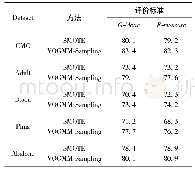
对比表2和表3还可以发现,4种分类模型中,无论是采样前还是采样后,gcForest算法的分类效果最好,为了清晰直观地对比4种分类模型的性能,如图6和图7所示,为4种分类模型的ROC曲线,对比表明深度森林gcForest算法的性能最佳。这是由于本文研究使用的DNA甲基化测序数据维度高,gcForest算法中的多粒度扫描结构通过采用滑动窗口对输入数据特征进行预处理,其表征学习能力得到进一步的提升。其次,将得到的特征输入到gcForest算法的级联森林中进行训练,级联森林将输入特征与原始特征结合,通过两层级联森林中的随机森林和完全随机森林的学习,相比于逻辑回归、随机森林和深度置信网络而言,能够更加充分地学习特征之间的相关性,因此获得的性能最佳。此外,相比于深度置信网络,gcForest算法的模型参数更少,容易训练,其在癌症分类研究中的小数据集方面更具优势。
| 图表编号 | XD00163026900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 刘超、吴申、郑一超、侯维岩 |
| 绘制单位 | 郑州大学信息工程学院、郑州大学信息工程学院、郑州大学信息工程学院、郑州大学信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}