《表1 数据表:一种基于混合采样的非均衡数据集分类算法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
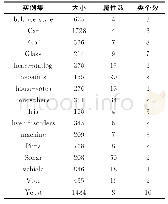
UCI数据库是加州大学欧文分校(University of California Irvine)提出的用于机器学习的数据库,UCI数据集是一个常用的标准测试数据集,为了评价本算法的性能,因此采用了UCI机器学习数据库中的6组有代表性的非均衡数据集,如表1是数据特征信息,数据是结构化数据,需要对其做特征缩放,将特征缩放至同一个规格.数据预处理将训练集和测试集归一化到[0,1]区间.如果样本集中包含几个类别,则选择其中一类样本或者将数量较少的几类样本合并后作为少数类,其余作为多数类.采用python语言进行实验,这6组非均衡数据集分别是credit数据集,pima数据集,page数据集,iris数据集,ecoli数据集,german数据集.每次实验将样本集随机划分,80%为训练集20%为测试集.
| 图表编号 | XD0079866100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.06.01 |
| 作者 | 张明、胡晓辉、吴嘉昕 |
| 绘制单位 | 兰州交通大学电子与信息工程学院、兰州交通大学电子与信息工程学院、兰州交通大学电子与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}