《表1 UCI数据集:基于字典学习的混合采样数据分类方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
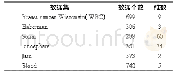
本文算法采用Python语言并在Python 3.5解释器上进行实现,所有实验都在内存为8 GB RAM,CPU频率为2.70 GHz计算机上运行。为了便于实验,在UCI的一些真实多视图数据集上验证了本文提出的方法,表1给出了5个多视图数据集的基本信息。
| 图表编号 | XD00109604500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 杨倩、于洪、李劼、谢永芳 |
| 绘制单位 | 重庆邮电大学计算智能重庆市重点实验室、重庆邮电大学计算智能重庆市重点实验室、中南大学冶金与环境学院、中南大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}