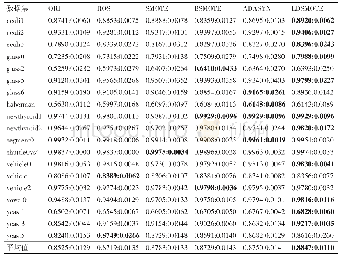
《表2 实验结果2:基于字典学习的混合采样数据分类方法》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
(2)实验在SensIT和Digit数据集上,对Sen?sIT的每个视图数据划分200个样本作为训练集,100个样本作为测试集;Digit的每个视图数据划分1 500个样本为训练集,500个样本为测试集。再以不同程度的采样频率对数据的每个视图进行数据采样生成混合采样数据,与对混合采样数据进行均值或中位数填充后在改进的处理多个数据表的FDDL算法进行对比。由表2看出,在某些场景下对混合采样数据进行均值或中位数填充等手段是不合理的,从而验证了混合采样数据分类算法的有效性。
| 图表编号 | XD00109604400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.10.01 |
| 作者 | 杨倩、于洪、李劼、谢永芳 |
| 绘制单位 | 重庆邮电大学计算智能重庆市重点实验室、重庆邮电大学计算智能重庆市重点实验室、中南大学冶金与环境学院、中南大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}