《表3 实验数据对比:基于卷积神经网络的单目深度估计》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
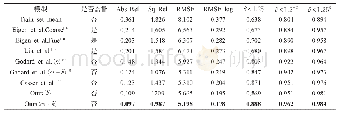
本文实验从各个场景下的街道中取样,将KITTI官方提供的697个未训练的视差图像用于评估实验结果,这个数据集中包括29个不同的场景。在表3中列出了该实验结果与相同条件下其他的实验数据之间的对比,其中Abs Rel、Sq Rel、RMSE、RMSE log这4个指标的数值越小越好,δ<1.25,δ<1.252,δ<1.253这3个指标为越大越好。性能均优于现有的算法。标题后面的“k”表示使用KITTI数据集训练,“cs+k”表示使用KITTI和Cityscapes两个数据集训练。从实验效果图中抽取了几张有代表性的图像,在图5中展示了本文实验的效果图与Godard等人的实验效果图对比,可以看出,使用空洞卷积提取特征,除了可以正确估计深度外,可以将原图不同的物体清晰的表现出来,可以增强模型对图像整体的感知,一些原本与背景融合的物体重新展现出来。但是如果使用扩张率过大的卷积核,反而会使图像变模糊,不能拟合出正确的图像。在第一个例子中,例如原图中与背景融合的电线杆在我们的效果图中完整的展现出来,并没有出现断裂,第二个例子地上的柱子和地面完全分割开来,第三个例子体现出人物和树木等事物的轮廓更为清晰。通过对比可以看出,如果图像中出现与远处事物颜色相近的物体,在Godard的算法表现欠佳,而在本实验中可以准确表达。图6选取了一些具体的事物的差别。Cityscapes数据集中测试的效果图如图7所示。
| 图表编号 | XD00163026400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 王欣盛、张桂玲 |
| 绘制单位 | 天津工业大学计算机科学与技术学院、天津市自主智能技术与系统重点实验室、天津工业大学计算机科学与技术学院、天津市自主智能技术与系统重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}