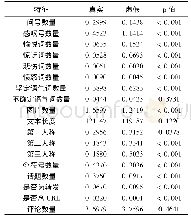
《表1 语言统计特征在真实与虚假类别文本的平均值及p值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
为验证以上假设,在一个新闻样本数据集(疫情期间互联网虚假新闻检测数据集)上构建表1中所示的语言统计特征,并计算每个特征在真实与虚假新闻样本中的平均值及p值(见表1)。统计结果表明在不同类别新闻文本中,多数统计特征都存在显著统计学差异(p≤0.05),只有“不确定语气词数量”、“文本长度”和“评论数量“在两类新闻中无显著统计学差异,提示语言统计特征具有较强的区分能力。从表1数据可以得出如下结论:
| 图表编号 | XD00160369400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.20 |
| 作者 | 楼靓 |
| 绘制单位 | 浙江交通职业技术学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}