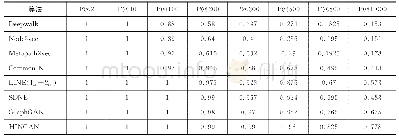
《表5 Precision值》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
DWES算法采用类似REA算法思想选取小部分之前存储的正类样本参与到当前分类器的训练,并且根据正类样本的数量取相同数量的负类样本形成平衡的样本对,利用多个平衡的样本对训练分类规则组成当前数据块的分类器,这样做相对于仅将部分正类样本拿到当前数据块进行训练的REA算法,或者利用自身样本进行上采样的DFGW算法来讲,能够增加对正类样本的识别度,并且避免产生噪声样本点,DWM、Learn++并没有对不平衡数据进行预处理,使得DWES算法在识别为正类样本的数据中有更多的是真正的正类样本,因此在Precision评价标准上相对于其他算法表现较好;在对新的数据块做测评时,因为新的数据块中有较多之前没出现过的正类样本,或者出现正类样本与负类样本概念互换(即发生概念漂移)的情况,DWES算法采用基于熵值的权重修改策略,动态寻找对综合表现影响最高的评价指标,通过评价指标值动态的更新分类器的权重,并不断淘汰权重较低的分类器,相对于仅采用单一评价指标来更新分类器的DWM算法和DWM IL算法或者通过时间的增加来减小分类器权重方法的Learn++算法能够分别增加正类样本跟负类样本的识别度,使得全部正类样本被识别为正类样本的数量大于其他算法,即Recall值优于其他算法;同时也会提高对负类样本的识别度,全部负类样本中识别为负类样本的数量大于其他算法,又由于Recall值优于其他算法,所以G-Mean值相对于其他算法表现较好;F-measure值与Precision值跟Recall值呈正相关性,由于Precision值跟Recall值均高于其他算法,因此F-measure值也会优于其他算法.AUC值是ROC曲线与坐标轴围成的面积,DWES通过多种机制提高正类样本的识别度,同时也会提升了负类样本的识别度,使得模型的鲁棒性更高,ROC去线下的面积相对于其他算法也会较大,最终使得AUC值优于其他算法.总体来说,DWES算法对比其他算法在处理带有概念漂移的不平衡数据流问题时有更好的性能.总体来说,DWES算法对比其他算法在处理带有概念漂移的不平衡数据流问题时有更好的性能.
| 图表编号 | XD00157803800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.01 |
| 作者 | 董明刚、张伟、敬超 |
| 绘制单位 | 桂林理工大学信息科学与工程学院、嵌入式技术与智能系统重点实验室、桂林理工大学信息科学与工程学院、嵌入式技术与智能系统重点实验室、桂林理工大学信息科学与工程学院、嵌入式技术与智能系统重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}