《表1 CNLI数据集分析》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
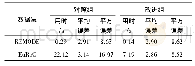
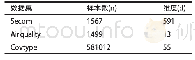
本文使用CCL2018中文文本蕴涵测评任务的数据集(chinese natural language inference,CNLI)进行实验,并且还在NTCIR-9RITE数据集上测试了本文模型泛化性。CNLI数据集用于训练的数据有90 000条,验证数据10 000条,测试数据10 000条,3种类别的数据比较平衡,数据具体分析统计见表1。
| 图表编号 | XD00154279500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.08.16 |
| 作者 | 严明、刘茂福、胡慧君 |
| 绘制单位 | 武汉科技大学计算机科学与技术学院、武汉科技大学智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、武汉科技大学智能信息处理与实时工业系统湖北省重点实验室、武汉科技大学计算机科学与技术学院、武汉科技大学智能信息处理与实时工业系统湖北省重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}