《表2 U-Net网络卷积运算加速前后对比》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
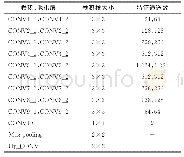
Pynq-Z1平台的FPGA中,完成一次单精度浮点数的乘累加运算的时间约为50个周期,其中包括对外部存储的两次读数据和一次写数据,运算过程和数据读写过程都很耗时。U-Net网络通用卷积运算硬件加速器的K值为8,理论上卷积运算的运算性能提升为400倍。但是ARM Cortex-A9的工作频率远大于FPGA的工作频率,两者的硬件机制和缓存机制也不同,实际的性能加速要远小于这个理论值。试验中,U-Net神经网络中25次卷积运算加速前后的运算时间和性能提升如表2所示。可以看出,大部分卷积运算在加速器中的运算速度是ARM运算性能的20倍左右,只有第一个卷积运算的运算速度提升低于10倍。原因是第一个卷积运算的输入通道数Cin等于3,不是K的整数倍,未充分利用硬件加速器的并行度。最终,所有卷积运算在卷积运算硬件加速器中的运算速度达到了ARM中运算速度的20.122倍。同时,整个U-Net网络的运算时间缩短为844.874 s,运算性能提升了19.690倍。
| 图表编号 | XD00150880100 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.20 |
| 作者 | 梅亚军、王唯佳、彭析竹 |
| 绘制单位 | 电子科技大学电子科学与工程学院、电子科技大学电子科学与工程学院、电子科技大学电子科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}