《表3 各算法的性能比较:大视场域的目标检测与识别算法综述》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
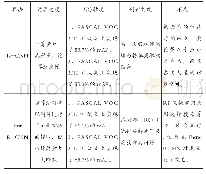
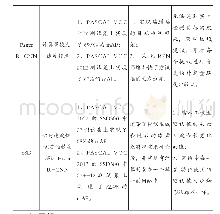
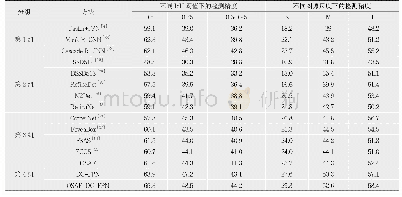
Yoshimi和Takahashi[36]提出一种适用于纠正垂直长物体的变形(站立的人或行人)的畸变校正方法———水平全景镶嵌(HPM),之后将处理完成的图片作为Faster R-CNN(faster region convolutional neural network)网络的输入,最终得到目标检测识别结果,此方法较基于DPM的方法在LAMR(logaverage miss rate)上有明显的下降,降低了11.58%。蔡成涛等[37]根据全景视觉系统特殊的成像原理建立全景系统的成像参数模型,根据此模型将得到LFOV图像的柱面展开图,同时根据目标的长宽比对YOLO的网络结构进行修改,使其适应目标在展开图的形状,其在全景目标检测速率上已经达到30.89frame/s,远远满足实时性要求,识别准确率也已经达到70%以上。徐佳等[38]通过球面投影校正的原理得到每张鱼眼图像的9个不同方向覆盖90°视角的平面透视图,然后运用LCNN(lookupbased convolutional neural network)[39]识别校正后的LFOV图像中的人脸,此方法在人脸识别准确率方面有显著提升且模型计算量减少。除特定人员目标外,邓军等[40]提出一种基于深度学习的火焰识别方法,此方法先将鱼眼图像投影到球面模型上,再对球面模型上获取火焰的候选区域进行畸变校正,将校正后的候选区域输入CNN(convolutional neural networks)中完成最终的火焰识别任务,在较大视场的情况下具有较低的误检率和漏检率。表3从预处理方法、特征提取网络、检测的时间、检测的准确率方面对上述算法进行总结对比。
| 图表编号 | XD00149529800 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.06.25 |
| 作者 | 李唐薇、童官军、李宝清、卢晓洋 |
| 绘制单位 | 中国科学院上海微系统与信息技术研究所微系统技术重点实验室、中国科学院大学、中国科学院上海微系统与信息技术研究所微系统技术重点实验室、中国科学院上海微系统与信息技术研究所微系统技术重点实验室、中国科学院上海微系统与信息技术研究所微系统技术重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}