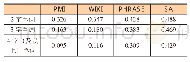
《表4 前5最相似词表中单词翻译对的数量和准确性》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
之后计算每个词对的余弦相似度,包括内部语言词和外部语言词.表4中列出了最相似的5个单词中出现其翻译词汇的数量统计.对于中文或英文单词,使用Parallel Trained Multi-BERT得到单词嵌入进行相似度计算,其在相对语言中的翻译词出现在最相似词汇表前5(Top@5)中的比例为41.73%,比Original Trained Multi-BERT的高出很多.可见拉近跨语言词汇的空间距离,能够从细粒度刻画翻译质量的优劣,因此能够在QE任务上带来一定的提升.
| 图表编号 | XD00140611000 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.28 |
| 作者 | 陆金梁、张家俊 |
| 绘制单位 | 中国科学院自动化研究所模式识别国家重点实验室、中国科学院大学、中国科学院自动化研究所模式识别国家重点实验室、中国科学院大学 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}