《表1 数据分布表:基于Spark的聚类算法优化与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
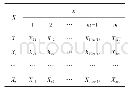
以下介绍数据分布,在聚类过程中,假设要聚类的数据为:X={X1,X2,…,Xn-1,Xn}。X是n个Rx(x=1,2,…,m-1,m)空间的数据。其基本的分布见表1。
| 图表编号 | XD00139791600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.15 |
| 作者 | 赵玉明、舒红平、魏培阳、刘魁 |
| 绘制单位 | 成都信息工程大学软件工程学院、成都信息工程大学软件自动生成与智能信息服务重点实验室、成都信息工程大学软件工程学院、成都信息工程大学软件自动生成与智能信息服务重点实验室、成都信息工程大学软件工程学院、成都信息工程大学软件自动生成与智能信息服务重点实验室、成都信息工程大学软件工程学院、成都信息工程大学软件自动生成与智能信息服务重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |






{kind=link}