《表2 数据文件:基于Spark的分布式健康大数据分析系统设计与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Spark的分布式健康大数据分析系统设计与实现》
特征向量选取原始数据的全部8个属性进行构建,特征:{“Start”,“End”,“Time in bed”,“Wake up”,“Stressful”,“Heartrate”,“Activity(steps/k)”,“Sleep quality”},将Start、End和Time in bed中的时间提取出来并转换成小时,再对每个维度的特征做变换后返回Dataframe,并增加标签列label,其中数值1表示好,数值0表示差,如表2所示。
| 图表编号 | XD00168921500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.15 |
| 作者 | 吴磊、欧阳赫明 |
| 绘制单位 | 北方工业大学信息学院、北方工业大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |

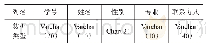



{kind=link}