《表4 实验预测结果:基于Spark的分布式健康大数据分析系统设计与实现》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于Spark的分布式健康大数据分析系统设计与实现》
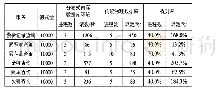
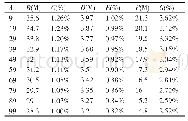
系统采用管道学习训练模型,即Pipeline。在机器学习中,通常有一系列的算法在数据中处理和学习。Spark MLlib提供的机器学习算法API,可以将多个算法组合成一个独立管道,之后管道会通过在参数网格上的不断爬行自动完成模型优化,最后系统进行预测时会使用通过管道训练得到的最优模型。预测结果中Prediction标签为最终预测结果,如表4所示。
| 图表编号 | XD00168921700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.15 |
| 作者 | 吴磊、欧阳赫明 |
| 绘制单位 | 北方工业大学信息学院、北方工业大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}