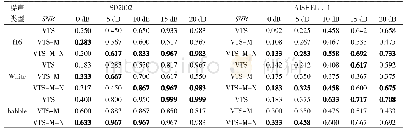
《表2 设定先验环境噪声为10 s时,在SD2002和AISHELL-1下传统VTS方法、VTS-M和VTS-M-N方法在混有不同信噪比的3种噪声下的正确识别率》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
将提出的方法应用到模型域,可以得到改进的模型域VTS方法(Vector Taylor Series-Model Improved,VTS-M)。从表2可以发现,VTS-M相比于特征域方法VTS-F,在低SNR下识别率有了进一步提高,但在高SNR下的下降更为明显。这是因为VTS-F方法中只用了噪声模型的均值进行MMSE估计得到干净的特征,而VTS-M方法分别使用了噪声模型的均值和方差对纯净说话人模型进行调整。当SNR比较高时,VTS-M方法由噪声模型不精确带来的影响更大。同样,当SNR比较低时,VTS-M方法补偿的效果更好。为了补偿VTS-M方法在高SNR下的识别率急剧下降的问题,本文使用了一种自适应方法对VTS-M方法进行调整,得到了新的改进的模型域VTS方法(VTS-M-N)。
| 图表编号 | XD00138859600 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.10 |
| 作者 | 张靖、俞一彪 |
| 绘制单位 | 苏州大学电子信息学院、苏州大学电子信息学院 |
| 更多格式 | 高清、无水印(增值服务) |
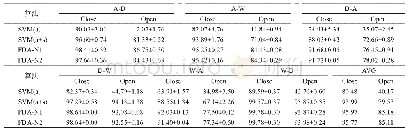


![表4 生命周期环境影响评估方法权重设定对比[10]](http://bookimg.mtoou.info/tubiao/gif/ZUQU202003008_01300.gif)


{kind=link}