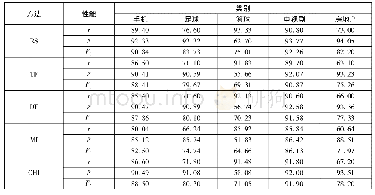
《表2 在6个数据集上4种方法的最高分类性能(F1)及对应的特征数(m)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
由表2可见,在6个数据集上WKNNFS达到的最高分类性能均高于其他方法.当达到最高分类性能时,WKNNFS在所有数据集上都优于CIFE方法,即达到最高分类性能时选取的特征数较少.WKNNFS与另外2种方法相比,当达到最高分类性能时,在4个数据集(hcc-data2、Sonar、Prostate和brain)上选取的特征数较少,在数据集Q_green上选取的特征数相差不大,而在数据集clean1上选取的特征数较多,这可能是因为遗传算法在搜索最优特征权重向量过程中陷入局部最优,而后又跳出局部最优(由图1(d)WKNNFS的分类性能曲线可见,在N=13和N=35附近曲线下降).
| 图表编号 | XD00138622500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.30 |
| 作者 | 李双杰、张开翔、王士栋、王淑琴 |
| 绘制单位 | 天津师范大学计算机与信息工程学院、天津师范大学计算机与信息工程学院、天津师范大学计算机与信息工程学院、天津师范大学计算机与信息工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}