《表3 各算法控制性能:基于即时学习的高炉炼铁过程数据驱动自适应预测控制》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于即时学习的高炉炼铁过程数据驱动自适应预测控制》
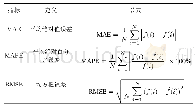
设定值跟踪实验中不同算法的控制效果和预测误差曲线分别如图8和图9所示,各算法的控制性能如表3所示,仿真控制时刻为250.铁水质量的初始设定值为[Si]=0.45%,MIT=1500℃.设定值分别在50,100,150和200时刻变化.对比3种控制方法,其中:N–MPC虽然利用非线性模型结构,但是该方法基于离线数据一次性建立全局模型,在模型失配时无法在线调整模型参数,因此预测误差较大且持续存在,被控曲线持续偏离设定工作点;RLS–MPC是一种基于递推最小二乘线性模型的预测控制方法,RLS–MPC与所提JITL–APC的主要区别在于模型的更新方式,由于被控对象是非线性系统,因此在改变设定工作点时,采用线性模型的RLS–MPC和JITL–APC均需要在线修正模型参数,而RLS–MPC在每个更新模型时刻只采集一组数据调整模型参数,如图9中100至200时刻[Si]预测误差曲线,RLS–MPC通过在线修正模型参数虽然能够逐渐减小预测误差,但需要较长的时间调整模型参数才能将预测误差降低到较小范围;相比RLS–MPC所提JITL–APC通过即时学习算法,在每个模型更新时刻查询多个相似数据样本对局部模型参数进行修正,该方法能够快速修正模型参数,在短时间内适应新的设定工作点,具有良好的设定值跟踪效果.
| 图表编号 | XD00135790300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 易诚明、周平、柴天佑 |
| 绘制单位 | 东北大学流程工业综合自动化国家重点实验室、东北大学流程工业综合自动化国家重点实验室、东北大学流程工业综合自动化国家重点实验室 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}