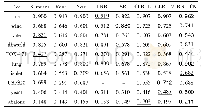
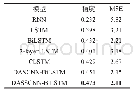
《表2 多个模型在4个数据集下的实验结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
这一结果是符合我们直观感受的,训练类样本越多,模型在训练类中所学习到的知识也就越多,在测试类种可以使用的辅助信息也就越有效,而且目前的零样本学习模型,并没有因为在训练类上具有较大的样本集合而导致过拟合现象,却反而拥有较强的测试类泛化能力.因此,在目前的零样本学习模型下,对于某些难以获得训练样本的测试类来说,如果想要较为方便地得到更好的零样本学习识别效果,直接增多易于获得的训练类个数以及训练类的样本,应该会是一个简单有效的方法.
| 图表编号 | XD00135234300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 张鲁宁、左信、刘建伟 |
| 绘制单位 | 中国石油大学(北京)自动化系、中国石油大学(北京)自动化系、中国石油大学(北京)自动化系 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}