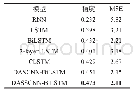
《表3 在IMDB数据集下模型对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
如表3、表4和表5所示,在IMDB数据集下的分类精度明显低于Yelp2014和Yelp2015的分类精度,原因在于IMDB数据集分为10类,而Yelp2014和Yelp2015分为5类,分类的难度随着类别数的增加而增加。且在三个数据集下,RNN的分类结果相对于LSTM明显较差,原因在于RNN在较长文本中产生了梯度消失或爆炸的问题,欠缺足够的长文本特征捕获能力,而LSTM弥补了该问题,提升了较长文本特征捕获能力。BiLSTM的分类效果略好于LSTM,原因在于其同时捕获了文本的前向语义和后向语义信息,相对于LSTM,提取了更多的语义信息。2-layer LSTM在IMDB数据集中精度为0.401,MSE为3.18,在Yelp2014中精度为0.613,MSE为0.51,在Yelp2015中精度为0.625,MSE为0.45,分类效果明显优于LSTM在三个数据集中的0.398、3.21,0.610、0.57和0.617、0.55,原因在于利用了双层LSTM,提取了更多的文本特征,证明了多层LSTM的有效性。CLSTM则因为利用了缓存机制,通过不同的遗忘率,得到了更好的分类效果。在Yelp2015数据集中,BiLSTM的分类效果和2-layer LSTM、CLSTM几乎一致,而在IMDB和Yelp2014中,BiLSTM的分类精度和MSE分别为0.432、2.21和0.625、0.49,2-layer LSTM的分类精度和MSE分别为0.401、3.18和0.613、0.51,CLSTM的分类精度和MSE分别为0.429、2.67和0.624、0.49,BiLSTM的分类效果明显高于二者,原因在于对前后向语义信息的捕获,进一步证明了捕获文本前后向语义信息的有效性。
| 图表编号 | XD00163023200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.07.01 |
| 作者 | 刘发升、徐民霖、邓小鸿 |
| 绘制单位 | 江西理工大学信息工程学院、江西理工大学信息工程学院、江西理工大学应用科学学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}