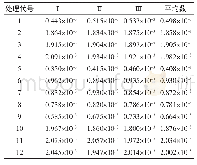
《表3 各算法在10 000个周期内累积的遗憾》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
所有实验的结果显示在表3中,由于空间限制,Bootstrapped DQN在表中表示为BDQN。此外,6.1节的实验结果即表中K=10,N=20所示的结果。在表3中,能在10 000个周期内学习到最优策略的算法的遗憾用加粗字体显示,可以看到DQN在所有的实验设置中都没能在10 000个周期内找到最优策略,而Bootstrapped DQN只有当K=10、N=10(格子世界的规模减小)或K=30、N=20(学习器的数量增加)时,才能在10 000个周期内学习到最优策略,而BBDQN在所有设置下都能在10 000个周期内学习到最优策略。从表3中还可以看出,当格子世界的规模较小时(N=10),BBDQN算法和Bootstrapped DQN算法的性能相差不大,而且由于BBDQN加入了随机初始化的先验网络,BBDQN的性能甚至略低于Bootstrapped DQN,但是当格子世界的规模增加时,本文提出的BBDQN算法的优越性就愈发明显,这也是BBDQN更适合解决深度探索问题的体现;此外,BBDQN算法的性能并不会随着学习器的数量增加而增加,这就意味着BBDQN的空间需求低于Bootstrapped DQN,因为学习器的数量越多,就需要越多的空间来存储每个学习的参数,且这些算法都是使用神经网络作为函数逼近器,每个网络的参数都是百万级的,而BBDQN并不像Bootstrapped DQN一样要通过增加学习器的数量来提高算法性能(如表3所示),因此BBDQN的空间需求低于Bootstrapped DQN。
| 图表编号 | XD00134721400 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 杨珉、汪洁 |
| 绘制单位 | 中南大学信息科学与工程学院、中南大学信息科学与工程学院 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}