《表9 在两种语料上模型数量对比结果》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
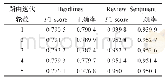
与此同时,本文对比了上述三种分词方法的模型数量,结果如表9所示。与多模型相比,在PKU语料上,模型数量由4 686减少到1 854,减少幅度近五分之三;在MSR语料上,模型数量由原来的5 151减少到2 299,减少幅度近二分之一。说明本文的实验方法在提高F值的同时大幅度减少了模型数量,节约了模型存储成本。
| 图表编号 | XD00134596900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.02.01 |
| 作者 | 李对红、王裴岩、张桂平、张少阳 |
| 绘制单位 | 沈阳航空航天大学人机智能研究中心、沈阳航空航天大学人机智能研究中心、沈阳航空航天大学人机智能研究中心、沈阳航空航天大学人机智能研究中心 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}