《表2 使用本文方法的美国手语字母分类混淆矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
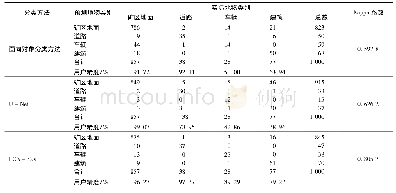
对于美国手语字母数据集,如图4(b),训练集和测试集的比例为9∶1,随机从数据集中抽取10%作为测试集.将旋转角度作为特征进行SVM分类时发现,对于美国手语字母a和c,由于参与测试的人员做手势时,并不是严格按照手势图进行比对,故对于不同的测试人员具有较大差异性.利用本文方法达到85.24%的分类识别准确率,美国手语字母手势分类的混淆矩阵如表2所示.
| 图表编号 | XD00134443300 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.01.01 |
| 作者 | 缪永伟、李佳颖、刘家宗、陈佳舟、孙树森 |
| 绘制单位 | 浙江理工大学信息学院、浙江理工大学信息学院、浙江理工大学信息学院、浙江工业大学计算机科学与技术学院、浙江理工大学信息学院 |
| 更多格式 | 高清、无水印(增值服务) |





{kind=link}