《表2 算法识别精度统计表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
如表2所示为基于VIPeR数据库进行10次重复独立实验,计算平均值作为识别精度的测试结果。如表2所示,给出了rank-1、rank-5、rank-10和rank-20识别精度的统计结果。从表中数据可以清楚地看出,本文算法在所有指标上均取得了最优的识别结果,尤其在rank-1的识别精度上,相较于MLAPG算法精度提升了7.79%。此外,本文给出了迭代次数c=2、β=0.3,c=1、β=0.8以及c=1、β=0.3三种参数条件下的识别精度。从结果可以看出,迭代次数增加虽然能够一定程度上提升rank-1的识别精度,但使得rank>5的识别精度存在显著下降。而当β=0.3时,rank-1具有稳定的识别精度,且能保证rank>1的识别精度。训练数据量p=316,即316个行人的数据用于训练。
| 图表编号 | XD00133707200 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.15 |
| 作者 | 宋丽丽、李彬、赵俊雅、刘国峰 |
| 绘制单位 | 成都理工大学工程技术学院、武汉轻工大学机械工程学院、武汉理工大学理学院、武汉理工大学理学院 |
| 更多格式 | 高清、无水印(增值服务) |




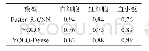
{kind=link}