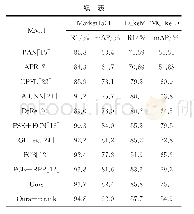
《表2 现有的并行化统计算法列表》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
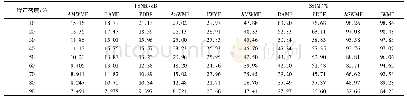
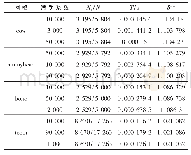
大数据挖掘分析子系统当前主流趋势是利用Spark在迭代计算和内存计算上的优势,将并行的机器学习算法与统计算法运行在Spark上。至于Spark的实现方式,则是集成MLLib。MLlib是Spark对常用的机器学习算法的实现库,支持常见的机器学习问题。现有常见的机器学习并行算法和并行化统计算法分别如表1和表2所示。
| 图表编号 | XD00131657700 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.03.01 |
| 作者 | 孙天伟 |
| 绘制单位 | 中兴通讯股份有限公司 |
| 更多格式 | 高清、无水印(增值服务) |



{kind=link}