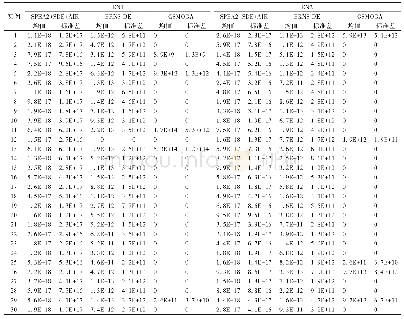
《表2 不同权重参数α下hMuLab算法的实验结果(平均值±标准差)》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
ML-kNN算法的实验结果表明,当近邻个数为6时,结果总体上最好,所以在进行hMuLab算法实验时,直接选取k=6作为加权k近邻的近邻个数。进而讨论参数α的取值对实验结果的影响。当α=0时,只考虑样本邻域信息,α=1时只考虑特征信息。hMuLab算法的实验结果如表2所示,当只考虑样本邻域信息(α=0)或者只考虑特征信息(α=1)时,结果都不理想,且α=0时的Hamming Loss、Ranking Loss和Coverage比α=1时的值要低,Average Precision比α=1时的值要高,说明从总体而言,α=0的分类结果要优于α=1时的分类结果。进而推断,对于静息态fMRI数据的多标签分类而言,考虑其邻域信息很重要,是在考虑特征信息基础上的重要补充。从表2也能看出,当α=0.5(特征信息权重等于邻域信息权重)时,结果总体上是最好的,α=0.25(邻域信息权重较大)时的结果稍次于α=0.5,但是比α=0.75(特征信息权重较大)的结果要好,进一步说明了考虑邻域信息的重要性。
| 图表编号 | XD00129377500 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2020.04.01 |
| 作者 | 吴怊慧 |
| 绘制单位 | 北京交通大学计算机与信息技术学院 |
| 更多格式 | 高清、无水印(增值服务) |


{kind=link}