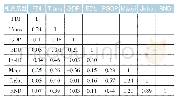
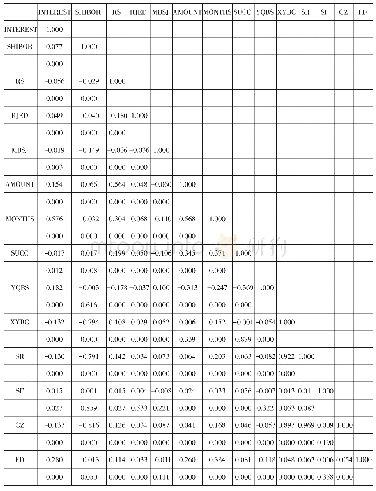
《表3 筛选后的特征变量之间相关性系数矩阵》
 提示:宽带有限、当前游客访问压缩模式
提示:宽带有限、当前游客访问压缩模式
本系列图表出处文件名:随高清版一同展现
《基于最大相关最小冗余-随机森林算法的多联机系统在线故障诊断策略研究》
已选定6个特征变量,利用网格搜索和十折交叉验证优化3个常用的故障检测和诊断模型,分别为随机森林、决策树和支持向量机。随机森林模型优化一般选择对mtry和ntree参数进行优化,其中mtry用来确定结点中用于二叉树的变量个数;ntree可以确定随机森林中树的数目。通过网格搜索和十折交叉验证最终从mtry=c(2,3,4,5,6),ntree=c(50,100,150,200,250,300,350,400,500,750,1,000)中确定最佳参数组合为mtry=5,ntree=300。在决策树模型中对cp参数进行优化,cp是指每一步拆分后,模型的拟合优度所必须提高的程度。对cp参数在10-8、10-7、10-6、10-5和10-4间寻优,当cp=10-5时,决策树故障诊断模型的错误率最低。支持向量机模型针对cost和gamma参数进行优化,在R语言的e1071包中,cost为惩罚因子,表示对支持向量机在优化模型时对导致模型预测效果变差的因素的惩罚力度,默认值为1。gamma是选择径向基核函数作为kernel后,该函数自带的一个参数。它隐含地决定了数据映射到特征空间后的分布,gamma值越小,支持向量越多。经过一定试算后,确定惩罚因子cost和核参数gamma的范围分别为cost=c(4,5),gamma=c(4,5,6),最后确定cost=5,gamma=6时模型最优。
| 图表编号 | XD00128151900 严禁用于非法目的 |
|---|---|
| 绘制时间 | 2019.12.01 |
| 作者 | 刘倩、李正飞、陈焕新、王誉舟、徐畅 |
| 绘制单位 | 华中科技大学能源与动力工程学院、华中科技大学能源与动力工程学院、华中科技大学能源与动力工程学院、华中科技大学能源与动力工程学院、华中科技大学能源与动力工程学院 |
| 更多格式 | 高清、无水印(增值服务) |




{kind=link}